

پدیده بیشبرازش (Overfitting) و راهکارهای مقابله با آن
همانطور که میدانید ساختن یک مدل یادگیری ماشین فقط تغذیهی دادهها نیست، بلکه عوامل بسیاری وجود دارند که بر دقت هر مدل تأثیر میگذارند. به عنوان مثال، در دنیای واقعی هرگز یک مجموعه داده تمیز و کامل نخواهیم داشت. هر مجموعه داده دارای برخی قسمتهای عجیب و غریب، مفقود شده و یا دادههای نامتعادل است. با توجه به هدف الگوریتمهای یادگیری ماشین، ممکن است مدل برای به دست آوردن الگوی موجود در دادهها به صورت دقیق، مجبور باشد نویزهای موجود در داده را در خود جای دهد. در نتیجه، مدل به دست آمده به خوبی با داده های آموزش متناسب خواهد بود اما به اندازه کافی برای تشخیص نمونه های دیگر که در روند مدلسازی وارد نشدهاند، قدرت تعمیم نخواهد داشت.
هدف یک مدل یادگیری ماشین خوب این است که بتواند پس از یادگیری دادههای موجود در مجموعه داده آموزش، به هر مجموعه دادهای از حوزه مشابه تعمیم یابد. این ویژگی به ما این امکان را میدهد تا بتوانیم برای مجموعه دادههایی که مدل هرگز ندیده است عملیات پیش بینی را انجام دهیم. بنابراین، تعمیم پذیری مدل آموزش داده شده در فرآیند یادگیری حائز اهمیت زیادی میباشد.
در آمار از اصطلاح fit بودن به عنوان میزان نزدیکی مقدار پیشبینیشده توسط مدل به کلاس هدف یا مقدار واقعی استفاده میشود. وقتی یک مدل بیش از نیاز واقعی با داده fit شود، شروع به سازگاری خود با دادههای پرت و مقادیر نادرست میکند. در این حالت به اصطلاح گفته میشود مدل overfit شده است. در نتیجهی این پدیده، کارایی و دقت مدل کاهش مییابد.
در ادامه قبل از بررسی دقیقتر پدیدهی overfitting به تفاوت بین سیگنال و نویز میپردازیم تا درک بهتری از نحوهی یادگیری درست مدل داشته باشیم.
سیگنال در مقابل نویز
در مدلسازی، شما میتوانید «سیگنال» را به عنوان الگوی زیربنایی واقعی که میخواهید از دادهها بیاموزید، تصور کنید. در مقابل، «نویز» به اطلاعات بیربط یا تصادفی در یک مجموعه داده اشاره دارد. برای درک مفهوم نویز و سیگنال، مثالی از زندگی واقعی را بررسی میکنیم.
فرض کنید میخواهیم رابطه بین سن و سواد را در میان بزرگسالان مدل کنیم. اگر قسمت بسیار زیادی از جمعیت را به عنوان نمونه درنظر بگیریم، یک رابطه واضح بین سن و سواد پیدا خواهیم کرد که این همان سیگنال است. درصورتی که اگر همین کار را در مورد یک جمعیت محلی انجام دهیم، ممکن است رابطه موجود بین دادهها به درستی مشخص نشود؛ زیرا ممکن است تحت تأثیر دادههای پرت و تصادفی قرار گیرد. به عنوان مثال، یک بزرگسال زودتر به مدرسه رفته یا برخی از بزرگسالان توانایی تحصیل نداشتند و ...
نویز با سیگنال تداخل پیدا میکند. اینجاست که الگوریتمهای یادگیری ماشین وارد میشوند. یک الگوریتم با عملکرد خوب میتواند سیگنال را از نویز جدا کند. اگر الگوریتم مورد استفاده بیش از حد پیچیده یا انعطافپذیر باشد (مثلا دارای ویژگی های ورودی زیادی باشد یا به طور مناسب تنظیم نشده باشد)، در نهایت به جای پیدا کردن سیگنال، نویزها را به خاطر میسپارد. مدلی که نویز را به جای سیگنال آموخته است، overfit یا بیشبرازششده در نظر گرفته میشود؛ زیرا با مجموعه داده آموزشی fit است اما با مجموعه دادههای جدید و دیدهنشده تناسب چندانی ندارد.
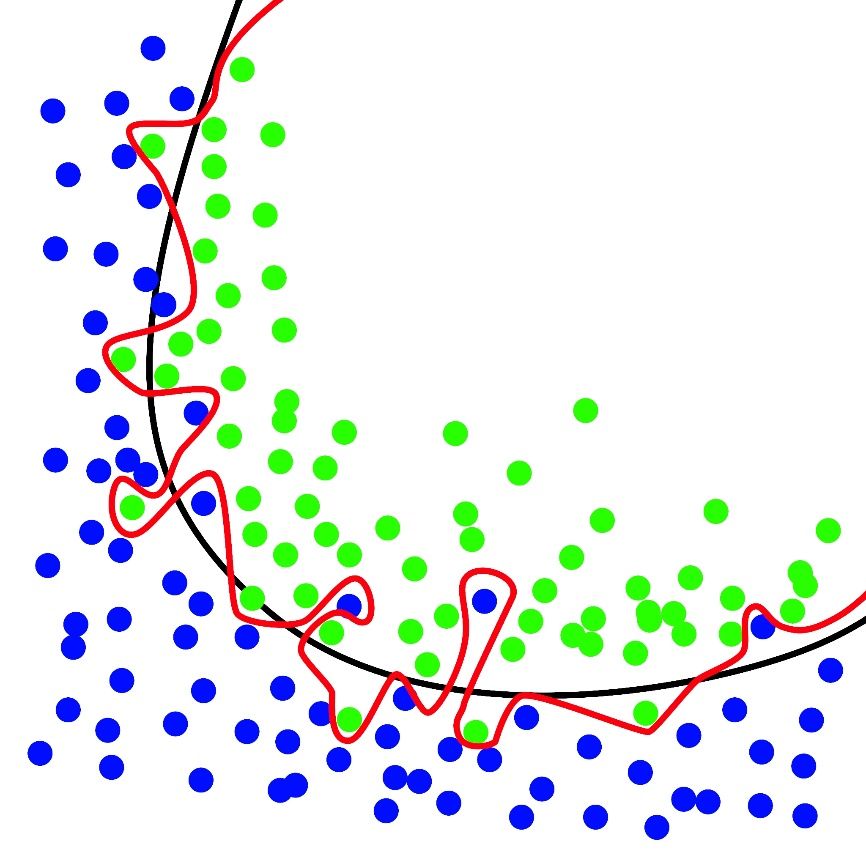
به عنوان مثال در مجموعه دادههای نشان داده شده در شکل، خط قرمز نمایانگر یک مدل overfit شده و خط سیاه نشان دهنده یک مدل fit شده است. گرچه خط قرمز به بهترین وجه دادههای آموزشی را دنبال میکند، اما بیش از اندازه به آن دادهها وابسته است و احتمالاً در مقایسه با خط سیاه، میزان خطای بالاتری در دادههای جدید و دیدهنشده خواهد داشت.
مقایسه Overfitting و Underfitting
قبل از این که بیشتر در زمینه overfitting صحبت کنیم، نگاهی به مفهوم underfitting میاندازیم. هنگامی که ما یک مدل را آموزش میدهیم، سعی میکنیم چهارچوبی را ایجاد کنیم که بتواند ماهیت یا کلاس اقلام موجود در مجموعه داده را بر اساس ویژگیهایی که آن موارد را توصیف میکنند، پیشبینی کند. یک مدل باید بتواند یک الگو را در یک مجموعه داده توضیح دهد و دادههای آینده را بر اساس این الگو پیشبینی کند. هر چه مدل رابطه بین ویژگیهای مجموعهی آموزشی را بهتر توضیح دهد، مدل ما از تناسب بیشتری برخوردار است و به اصطلاح fit است.
مدلی که رابطهی بین ویژگیهای دادههای آموزشی را ضعیف توضیح دهد و در نتیجه نتواند نمونه دادهها را به طور دقیق طبقهبندی کند، دچار underfitting روی دادههای آموزشی است. underfitting اغلب در هنگام تلاش برای طراحی یک مدل خطی با دادههای غیر خطی رخ میدهد. همچنین زمانی که دادههای کافی برای ایجاد یک مدل دقیق وجود نداشته باشد نیز underfit شدن مدل وجود دارد. دادههای آموزشی بیشتر یا ویژگیهای بیشتر اغلب به کاهش underfitting کمک میکنند.
بنابراین چرا ما مدلی را ایجاد نمیکنیم که تمام دادههای آموزش را توضیح دهد؟ مگر هدف نهایی کسب بهترین دقت نیست؟ باید توجه کنیم ایجاد مدلی که الگوهای دادههای آموزشی را به خوبی فرا گرفته باشد، چیزی است که باعث overfitting میشود. مجموعه دادههای آموزشی و مجموعه دادههایی که مدل بعدا بر روی آنها تست میشود دقیقاً یکسان نخواهند بود اما با وجود تفاوتها، ویژگیهای کلیدی یکسانی نیز خواهند داشت. بنابراین، طراحی مدلی که مجموعه دادههای آموزشی را کاملاً توضیح دهد به این معنی است که شما رابطه بین ویژگیهایی که به مجموعه دادههای دیگر نیز به خوبی تعمیم مییابد را به دست آوردهاید. در ادامه با بررسی یک مثال تلاش میکنیم تا این موضوع مشخصتر شود.
مثالی از Overfitting
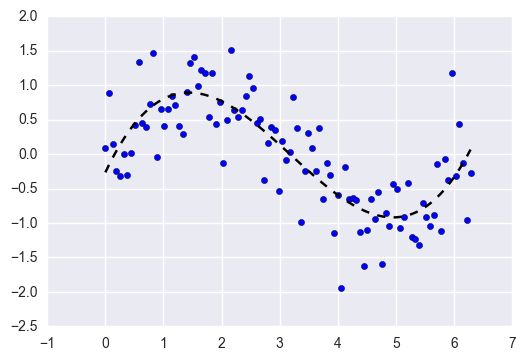
در این مثال overfitting و underfitting را بررسی میکنیم و این که چگونه میتوان از رگرسیون خطی با ویژگیهای چندجملهای برای تقریب توابع غیرخطی استفاده کرد. نمودار نارنجی تابعی را نشان میدهد که میخواهیم تقریب بزنیم و این تابع بخشی از تابع کسینوس میباشد. علاوه بر این، نمونههای تابع اصلی و تقریب مدلهای مختلف نیز نمایش داده شده است. مدلها دارای ویژگیهای چندجملهای از درجات مختلف هستند.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score
def true_fun(X):
return np.cos(1.5 * np.pi *X)
np.random.seed(0)
n_samples = 30
degrees =[1, 4, 15]
X = np.sort(np.random.rand(n_samples))
y = true_fun(X) + np.random.randn(n_samples) * 0.1
plt.figure(figsize=(14, 5))
for i in range(len(degrees)):
ax = plt.subplot(1, len(degrees), i + 1)
plt.setp(ax, xticks=(), yticks=())
polynomial_features = PolynomialFeatures(degree=degrees[i], include_bias=False)
linear_regression = LinearRegression()
pipeline = Pipeline([("polynomial_features", polynomial_features), ("linear_regression", linear_regression)])
pipeline.fit(X[:, np.newaxis], y)
# Evaluate the models using cross validation
scores = cross_val_score(pipeline, X[:, np.newaxis], y, scoring="neg_mean_squared_error", cv=10)
X_test = np.linspace(0, 1, 100)
plt.plot(X_test, pipeline.predict(X_test[:, np.newaxis]), label="Model")
plt.plot(X_test, true_fun(X_test), label="True function")
plt.scatter(X, y, edgecolor='b', s=20, label="Samples")
plt.xlabel("x")
plt.ylabel("y")
plt.xlim((0, 1))
plt.ylim((-2, 2))
plt.legend(loc="best")
plt.title("Degree {}nMSE = {:.2e}(+/- {:.2e})".format(degrees[i], -scores.mean(), scores.std()))
plt.show()
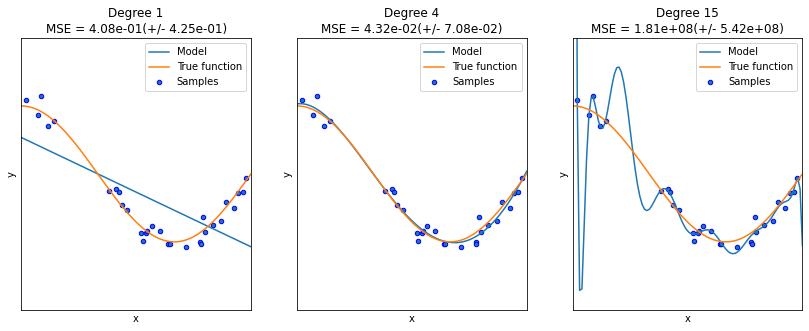
میبینیم که یک تابع خطی (چند جمله ای با درجه 1) برای fit شدن با نمونههای آموزشی کافی نیست. این حالت همان underfitting است. چندجملهای درجه 4 تقریباً تابع اصلی را تقریب میزند. با این حال، برای درجات بالاتر، مدل دچار حالت overfitting روی دادههای آموزشی میشود؛ یعنی نویز دادههای آموزشی را میآموزد.
دلایل وقوع Overfitting
علت وقوع این پدیده ممکن است ناشی از پیچیده باشد اما به طور کلی، میتوانیم آنها را به سه نوع دستهبندی کنیم:
- یادگیری نویز در مجموعه آموزش
- پیچیدگی مدل
- روشهای مقایسهای که در الگوریتمهای هوش مصنوعی به صورت فراگیر وجود دارند
یادگیری نویز در مجموعه آموزش
همان طور که پیشتر بحث شد، هنگامی که مجموعه آموزشی از نظر اندازه خیلی کوچک باشد، یا دارای اطلاعات نمایانگر کمتری باشد، یا نویز زیادی داشته باشد، این وضعیت باعث میشود که نویزها و دادههای پرت شانس زیادی برای یادگیری داشته باشند و بعداً به عنوان مبنای پیشبینیها عمل کنند. بنابراین، یک الگوریتم با عملکرد خوب باید بتواند دادههای نماینده را از نویز تشخیص دهد.
پیچیدگی مدل
در تعیین میزان پیچیدگی یک مدل مفهومی به نام تعادل بین واریانس و بایاس مطرح میشود که به تعادل بین دقت و سازگاری اشاره دارد. وقتی الگوریتمها ورودیهای بسیار زیاد دارند، مدل به طور متوسط با سازگاری کمتری دقیقتر می شود. این وضعیت به این معنی است که مدلها میتوانند در مجموعه دادههای مختلف به شدت متفاوت عمل کنند. در ادامه به بررسی این دو مفهوم و ارتباط آنها با پیچیدگی مدل میپردازیم.
واریانس (Variance) و بایاس (Bias) هر دو شکلهای مختلفی از خطای پیش بینی در یادگیری ماشین هستند. سازش بین واریانس و بایاس زیاد (Bias Variance Trade-off) مفهوم بسیار مهمی در آمار و یادگیری ماشین است که بر تمام الگوریتمهای تحت نظارت یادگیری ماشین تأثیر میگذارد. این trade-off تأثیر بسزایی در تعیین پیچیدگی و overfitting برای هر مدل یادگیری ماشین دارد.
بایاس (Bias)
بایاس تفاوت بین پیشبینیهای مورد انتظار از مدل شما و مقادیر واقعی است. تصور کنید که یک مدل رگرسیون خطی را به مجموعه دادهای که دارای الگوی غیر خطی است، fit کنید:
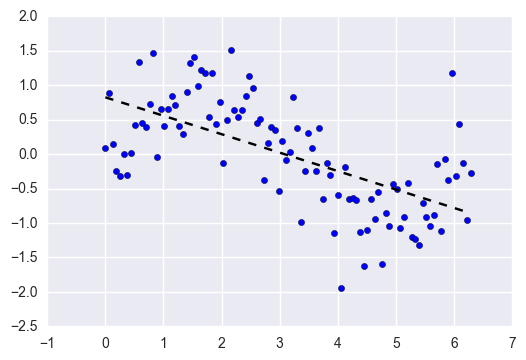
هر چقدر هم مشاهدات بیشتر جمعآوری کنید، یک رگرسیون خطی نمیتواند منحنیهای موجود در آن دادهها را مدلسازی کند. این همان پدیدهایست که به عنوان underfitting شناخته میشود.
واریانس (Variance)
واریانس به حساسیت الگوریتم شما نسبت به مجموعه خاصی از دادههای آموزشی اشاره دارد. الگوریتمهایی با واریانس بالا بسته به مجموعهی آموزش، مدلهای بسیار متفاوتی تولید خواهند کرد.

الگوریتمی را در نظر بگیرید که باعث برازش مدلی بدون محدودیت و فوق العاده انعطاف پذیر در همان مجموعه داده بالا میشود. همانطور که میبینید، این مدل بدون محدودیت، مجموعه آموزشی را با تمام نویزها حفظ کرده است که این پدیده همان overfitting میباشد.
تعادل بین واریانس و بایاس
الگوریتمهای بایاس بالا-واریانس کم پیچیدگی کمتری دارند و دارای ساختاری ساده ولی غیرمنعطف هستند. آنها مدلهای سازگار، اما به طور متوسط با دقت کم را آموزش خواهند داد؛ مانند الگوریتمهای خطی یا پارامتریک مثل رگرسیون، Naive Bayes و …
الگوریتمهای بایاس کم-واریانس بالا ساختار پیچیدهتر و در عین حال انعطافپذیر دارند. آنها مدلهایی را آموزش میدهند که به طور متوسط ناسازگار اما دقیق هستند؛ مانند الگوریتمهای غیرخطی یا غیرپارامتری مثل درخت تصمیم، نزدیکترین همسایه و ...
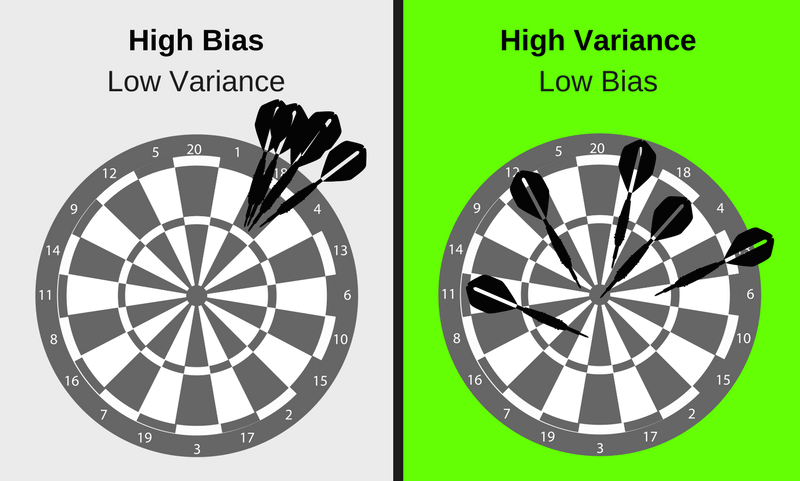
وجود trade-off بین بایاس و واریانس مشخصکنندهی میزان پیچیدگی مدل است؛ زیرا یک الگوریتم نمیتواند همزمان هم پیچیده و هم ساده باشد.
برای برخی از حالات، ممکن است مقدار هر دو خطا در بعضی از الگوریتمها کمتر از بقیهی خطاها باشند. به عنوان مثال، روشهای گروهی (Ensebmle) مانند جنگل تصادفی (Random Forest) اغلب در عمل بهتر از سایر الگوریتمها عمل میکنند. توصیه ما این است که همیشه برای هر مسالهای چندین الگوریتم معقول را امتحان کنید.
برای ساختن یک مدل پیشبینیکننده خوب، باید تعادلی بین بایاس و واریانس پیدا کرد که خطای کل را به حداقل برساند. در نتیجه، این تعادل مطلوب منجر به مدلی میشود که نه overfit و نه underfit شده باشد که این همان هدف نهایی یادگیری ماشین تحت نظارت است، یعنی جدا کردن سیگنال از مجموعه داده در حالی که نویز را نادیده میگیرد.
روشهای مقایسهای که در الگوریتمهای هوش مصنوعی به صورت فراگیر وجود دارند
در طی این فرآیندها، ما همواره چندین آیتم را بر اساس نمرات یک تابع ارزیابی مقایسه میکنیم و آیتمی با حداکثر امتیاز را انتخاب میکنیم. با این حال، این فرآیند احتمالاً آیتمهایی را انتخاب میکند که هیچ تاثیری در بهبود دقت طبقهبندیکننده نداشته و یا حتی باعث کاهش دقت طبقهبندی میشوند.
روشهای تشخیص بیشبرازش
یک چالش کلیدی که در تشخیص هر نوع برازش (مانند overfitting ،fit و underfitting) وجود دارد این است که قبل از تست کردن دادهها تشخیص آن تقریباً غیرممکن است. این مورد به ویژگیهای ذاتی overfitting که ناتوانی در تعمیم مجموعه داده است اشاره دارد. بنابراین میتوان دادهها را به زیرمجموعههای مختلف تفکیک کرد تا آموزش و آزمایش آسان شود. دادهها به دو بخش اصلی تقسیم میشوند، یعنی مجموعه داده آزمایشی و مجموعه داده آموزشی.
تکنیک تقسیم ممکن است بر اساس نوع مجموعه داده متفاوت باشد و میتوان از هر نوع تکنیک تقسیم استفاده کرد.
- اگر مدل در مجموعه دادههای آموزش بسیار بهتر از مجموعه دادههای آزمایش عمل میکند، به احتمال زیاد مدل overfit شده است؛ برای مثال، فرض کنید مدل با دقت 99٪ روی مجموعه داده آموزش عمل میکند، اما دقت آن روی مجموعه داده آزمایش تنها 50-55٪ است. این مدل overfit است و قابلیت تعمیمپذیری ندارد.
- اگر مدل در مجموعه دادههای آزمایش بهتر از مجموعه دادههای آموزش عمل کند یا به صورت کلی بر روی دادههای آموزش دقت خوبی نداشته باشد، به احتمال زیاد دچار underfitting شده است.
- اگر مدل در هر دو مجموعه دادههای آموزش و آزمایش خوب عمل کند، مدل بهترین تناسب را دارد؛ به عنوان مثال، مدل ما دقت 90٪ روی مجموعه آموزش و دقت 88-92٪ روی مجموعه داده آزمایشی دارد. در این حالت این مدل fit شده است و مناسب مساله است.
- اگرچه تشخیص overfitting موثر است، اما مشکل را حل نمیکند. چندین تکنیک برای جلوگیری از این پدیده وجود دارد که در ادامه آنها را بررسی میکنیم.
روشهای جلوگیری از overfitting
برای جلوگیری از overfitting، روشهای مختلفی وجود دارد که در ادامه چند مورد از آنها بررسی میشوند.
استفاده از Cross-validation
این روش یک اقدام پیشگیرانه قوی در برابر overfitting است. برای این کار از دادههای اولیه آموزشی چند بخش کوچک آموزش - تست ایجاد میشود از این تقسیمها برای تنظیم مدل استفاده میشود. در K-fold cross-validation، دادهها به k زیرمجموعه تقسیم میشوند که هر کدام از آنها یک fold نامیده میشوند. سپس، به طور مکرر الگوریتم را بر روی k-1 fold آموزش داده میشود و از یک fold باقیمانده به عنوان مجموعه آزمایش (که «holdout fold» نامیده میشود) استفاده میشود.
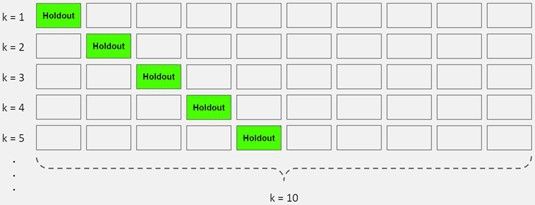
اعتبارسنجی متقابل به شما این امکان را میدهد که هایپرپارامترها را فقط با مجموعه آموزشی اصلی تنظیم کنید و مجموعه آزمایش را برای انتخاب مدل نهایی خود به عنوان یک مجموعه داده واقعاً دیده نشده نگه دارید.
گسترش دادههای آموزشی
در یادگیری ماشین، الگوریتم تنها عاملی نیست که بر دقت طبقهبندی نهایی تأثیر میگذارد. کیفیت و کمیت مجموعه دادههای آموزشی در بسیاری از موارد، به ویژه در زمینه یادگیری تحت نظارت، به طور قابل توجهی بر دقت نهایی تاثیر میگذارند. آموزش مدل در واقع فرآیند تنظیم پارامترهای آن است. پارامترهای تنظیم شده به خوبی از اثر overfitting و همچنین underfitting جلوگیری میکنند. برای تنظیم این پارامترها، مدل برای یادگیری به نمونههای کافی نیاز دارد. مقدار نمونهها متناسب با تعداد پارامترها است و هرچه مدل پیچیدهتر باشد، پارامترهای بیشتری باید تنظیم شوند. به عبارت دیگر، یک مجموعه دادهی گسترده میتواند دقت پیشبینی را به ویژه در مدلهای پیچیده تا حد زیادی بهبود دهد.
اگر امکان جمعآوری دادههای بیشتر نبود، میتوان مجموعه دادههای موجود را متنوعتر جلوه داد. به همین دلیل است که دادهافزایی (Data Augmentation) به طور گسترده به عنوان یک استراتژی کلی برای بهبود عملکرد قدرت تعمیم مدلها در بسیاری از زمینهها، مانند تشخیص الگو و پردازش تصویر مورد استفاده قرار می گیرد.
با این حال، افزایش حجم دادهها زمان آموزش را افزایش میدهد. علاوه بر این، دستیابی به دادههای آموزشی میتواند گران یا دشوار باشد؛ زیرا به مداخله انسانی زیادی مانند برچسب زدن نیاز دارد.
به طور خلاصه، عمدتا چهار رویکرد برای گسترش مجموعه آموزش وجود دارد:
- دادههای آموزشی بیشتری جمعآوری کنید.
- مقداری نویز تصادفی به مجموعه دادهی موجود اضافه کنید.
- مقداری از دادهها را از مجموعه داده های موجود به وسیله برخی پردازشها تغییر دهید.
- برخی از دادههای جدید را بر اساس توزیع مجموعه دادههای موجود تولید کنید.
کاهش پیچیدگی مدل
بیشبرازش مدل میتواند به دلیل پیچیدگی یک مدل اتفاق بیفتد، به گونهای که حتی با وجود حجم زیادی از دادهها، مدل هنوز هم روی مجموعه داده آموزشی overfit شود. کاهش پیچیدگی مدل میتواند از بیشبرازش آن جلوگیری کند.
برخی از اقدامات قابل اجرا شامل هرس درخت تصمیم یا کاهش تعداد پارامترها و استفاده از dropout در شبکههای عصبی است. سادهسازی مدل همچنین میتواند مدل را سبکتر و سریعتر کند.
حذف ویژگیها
اگرچه برخی از الگوریتمها دارای انتخاب خودکار ویژگیها هستند، برای تعداد قابل توجهی از الگوریتمها که این ویژگی را ندارند، حذف چند ویژگی نامربوط به صورت دستی از ورودیهای مدل میتواند تعمیم آن را بهبود بخشد. یکی از راههای انجام این کار، نتیجهگیری در مورد چگونگی fit شدن آن ویژگی در مدل است. این کار کاملاً شبیه اشکال زدایی کد به صورت خط به خط است. اگر ویژگیای نتواند ارتباط دادهها را در مدل توضیح دهد، میتوانیم آن ویژگی را شناسایی کنیم. در کل بهتر است از چند روش انتخاب ویژگی برای یک نقطه شروع مناسب استفاده شود.
توقف زودهنگام
وقتی یک الگوریتم یادگیری را به صورت مکرر آموزش میدهید، میتوانید نحوهی عملکرد مدل را در هر مرحله ارزیابی کنید. تا تعداد مشخصی از تکرارها، مدل روندی رو بهبود دارد و دقت در هر تکرار افزایش مییابد. با این حال، پس از نقطهای، توانایی مدل در تعمیم ضعیف میشود زیرا شروع به بیشبرازش بر روی دادههای آموزشی میکند. توقف زودهنگام به توقف روند آموزش قبل از گذشت مدل از آن نقطه اشاره میکند.
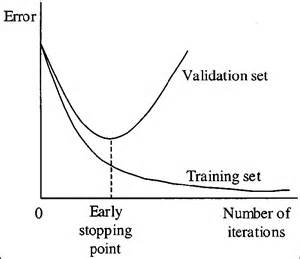
امروزه این تکنیک بیشتر در یادگیری عمیق استفاده میشود؛ در حالی که سایر تکنیکها (به عنوان مثال regularization یا نظمدهی) برای یادگیری ماشین کلاسیک ترجیح داده میشوند.
نظمدهی (Regularization)
به طور کلی، خروجی یک مدل میتواند تحت تأثیر چندین ویژگی قرار گیرد. با افزایش تعداد ویژگیها مدل پیچیدهتر میشود. یک مدل overfit شده تمایل دارد همهی ویژگیها را برای ایجاد خروجی در نظر بگیرد، حتی اگر برخی از آنها تأثیر بسیار محدودی بر خروجی نهایی داشته باشند، و یا حتی اگر برخی از آنها نویزهایی باشند که برای خروجی بیمعنی هستند.
جهت محدود کردن این موارد، دو نوع راه حل وجود دارد:
- فقط ویژگیهای مفید را انتخاب کرده و ویژگیهای غیرمفید را از مدل خود حذف کنیم.
- وزن ویژگیهایی را که تأثیر کمی بر طبقهبندی نهایی دارند، به حداقل برسانیم. به عبارت دیگر نیاز داریم که اثر ویژگیهای بیفایده را محدود کنیم. اما تشخیص ویژگیهای بیفایده همیشه کار سادهای نیست، بنابراین سعی میشود با به حداقل رساندن تابع هزینه، همه آنها را محدود کنیم.
برای انجام این کار، یک پنالتی به نام regularizer به تابع هزینه اضافه میشود که در فرمول زیر نشان داده شده است:
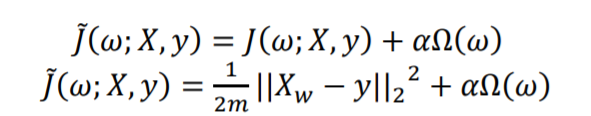
در این فرمولها ?(?; ?, ?) تابع هزینهی اصلی، ? وزن، ? مجموعه دادهی آموزش، ? مقادیر واقعی یا مقادیر لیبل ها، ? تعداد اعضای مجموعه آموزش، ? ضریب regularization و ?Ω(?) همان پنالتی اعمال شده میباشد.
در این جا میتوانیم از متد گرادیان کاهشی برای پیدا کردن مجموعه وزنها استفاده کنیم:
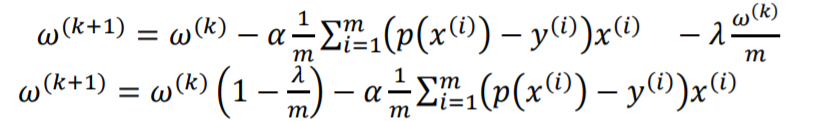
با توجه به فرمول های بالا در می یابیم که هرچه اندازه ? بیشتر شود میزان پنالتی کاهش مییابد. به عبارت دیگر، هرچه مجموعهی آموزش بزرگتر باشد، خطر بیشبرازش و اثر regularization کمتر خواهد بود.
روشهای مختلفی برای regularizaton وجود دارد که بسته به نوع یادگیری مورد استفاده میتوان از آنها استفاده کرد. انتخاب روش نظمدهی نیز اغلب یک هایپرپارامتر است، به این معنی که میتوان آن را از طریق cross-validation تنظیم کرد.
کلاس بندی جمعی (Ensembling)
گروهبندی یا Ensembling یکی از روشهای یادگیری ماشین است که پیشبینی ها را از چندین مدل جداگانه با هم ادغام میکند. چندین روش مختلف برای کلاس بندی جمعی وجود دارد، اما دو روش رایجتر آن عبارتند از bagging و boosting.
در پایان باید گفت که بیشبرازش یا overfitting یک مساله کلی در یادگیری ماشین تحت نظارت است که نمیتوان به طور کامل از آن اجتناب کرد. این امر میتواند به دلیل محدودیت اندازه دادههای آموزشی یا نویزی بودن دادهها باشد. همچنین این اتفاق میتواند به خاطر پیچیدگی الگوریتمها و نیاز آنها به تنظیم پارامترهای زیاد باشد؛ اما در پاسخ به اتفاق، الگوریتمهای متنوعی برای کاهش اثر برازش استفاده میشود که در این پست برخی از آنها را بررسی کردیم.